
Building a Data Lake for Ignition SCADA Data - Approach 1
Introduction
In industrial automation, data is everything. It powers how we design, run, monitor, and optimize plant operations. As operations scale, the volume of data grows quickly and if you're collecting it in real time, local storage alone doesn't cut it for long-term analytics or sustainability.
For this project, I was tasked with building a cloud-based data lake for an Ignition SCADA deployment. The goal was to securely and reliably offload raw SCADA data from the plant to the cloud, for easier storage, reporting, and future machine learning work. The client was already using AWS for other services, so integrating the data lake on the same platform made perfect sense.
This setup was done in two phases:
- Approach 1 (this document): Export SCADA data from the database to Amazon S3 via Python
- Approach 2 (next): Real-time MQTT-based data streaming using the Cirrus Link IIoT modules (after license upgrade)

Project Steps: Approach 1
Step 1: SCADA Sensor Data into Ignition
I first configured OPC UA tags in Ignition to bring in real-time process data from the PLCs. The tags were set to update frequently (1-second scan class) to match the nature of the plant's operations.
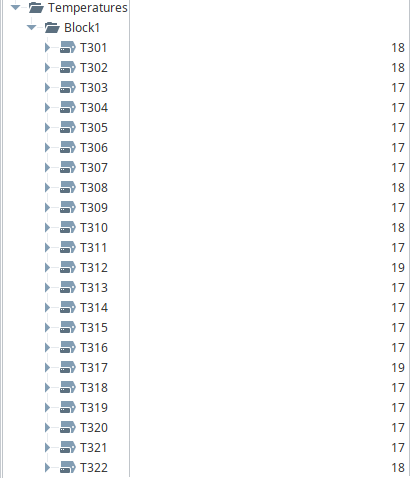
Step 2: Logging SCADA Data to a Local Database
To store the live data, I used Ignition's Transaction Groups to log tags into a local MySQL database. The goal was to persist sensor data every second for each active machine.
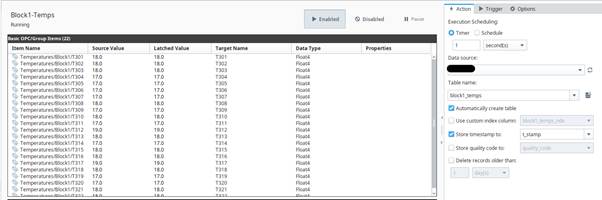
Step 3: Exporting Daily Data to Amazon S3
The plant runs 24/6, and the local DB was growing rapidly. To avoid bloating the server and to make data available remotely, I implemented a Python script that runs every midnight to:
- Extract that day’s data from MySQL
- Format it as a CSV
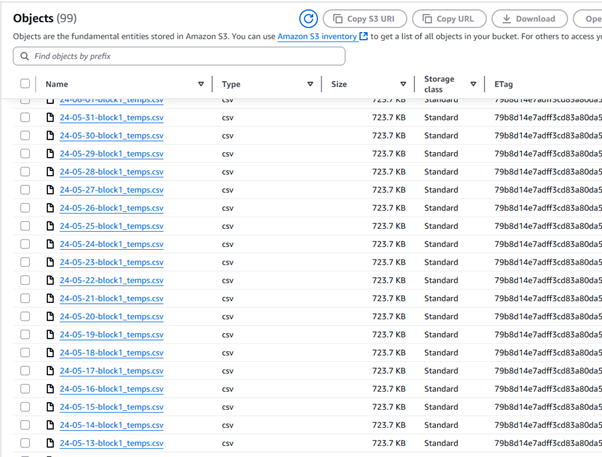
- Upload it to a designated S3 bucket
This approach ensures each day's data is offloaded consistently and stored in a format suitable for long-term analysis.
Why S3?
- S3 offers highly available, scalable storage
- It's cheaper long-term than keeping all data in RDS
- Easy to integrate with AWS analytics services
To automate the daily exports:
- I installed necessary Python packages (boto3, mysql-connector-python)
- Configured AWS CLI with aws configure
- Used Windows Task Scheduler to run the script every day at midnight
![]()
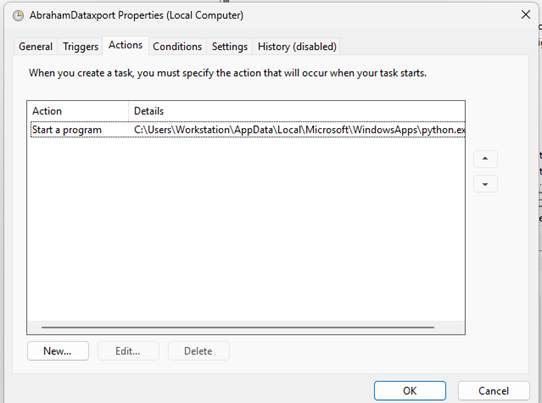
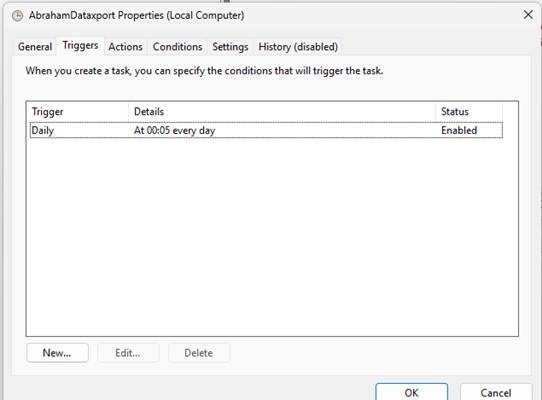
Python Export Script
import mysql.connector
import boto3
import csv
import os
from datetime import datetime
DB_CONFIG = {
'host': os.getenv('DB_HOST'),
'user': os.getenv('DB_USER'),
'password': os.getenv('DB_PASSWORD'),
'database': os.getenv('DB_NAME')
}
S3_BUCKET = os.getenv('S3_BUCKET')
S3_FOLDER = 'block1/'
TABLES = ['block1_temps']
TIME_COLUMN = 't_stamp'
def dataexport(table_name, conn, export_date):
cursor = conn.cursor()
query = f"""
SELECT * FROM {table_name}
WHERE DATE({TIME_COLUMN}) = %s
"""
cursor.execute(query, (export_date,))
rows = cursor.fetchall()
columns = [desc[0] for desc in cursor.description]
filename = f"{export_date.strftime('%y-%m-%d')}-{table_name}.csv"
with open(filename, 'w', newline='') as f:
writer = csv.writer(f)
writer.writerow(columns)
writer.writerows(rows)
cursor.close()
return filename
def upload_to_s3(filename, bucket, folder):
s3 = boto3.client('s3')
s3_key = f"{folder}{filename}" if folder else filename
s3.upload_file(filename, bucket, s3_key)
print(f"Uploaded: {filename} → s3://{bucket}/{s3_key}")
def main():
today = datetime.now().date()
conn = mysql.connector.connect(**DB_CONFIG)
try:
for table in TABLES:
filename = dataexport(table, conn, today)
upload_to_s3(filename, S3_BUCKET, S3_FOLDER)
os.remove(filename)
finally:
conn.close()
if __name__ == "__main__":
main()
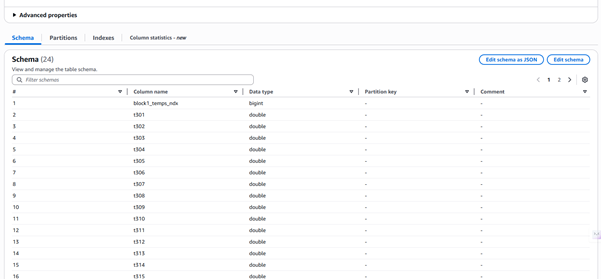
Step 4: AWS Glue - Making the Data Queryable
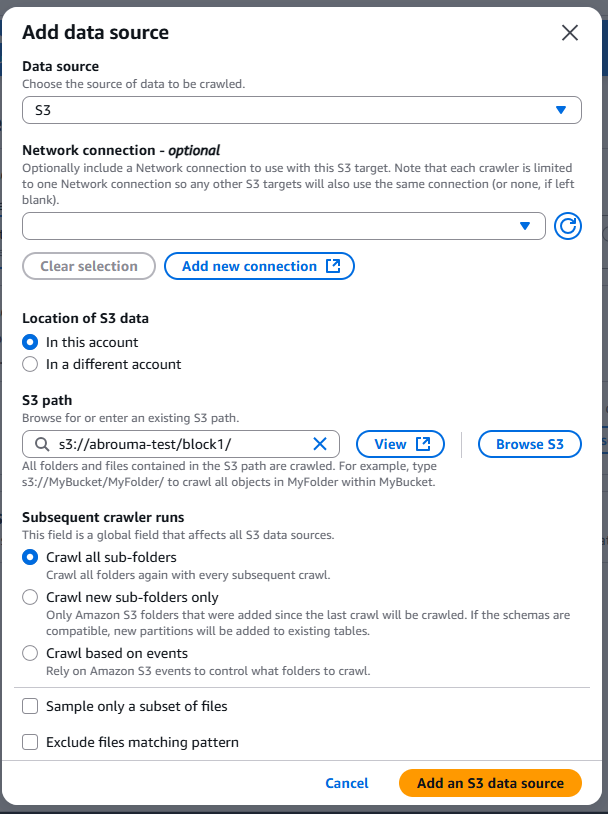
Once the CSVs are in S3, S3 itself doesn’t know how to interpret the files as it just stores them. To make this data queryable, I used AWS Glue Crawlers to:
- Scan the S3 folder structure
- Infer schema (columns, types, partitions)
- Create a table in the Glue Data Catalog
This essentially gave me a virtual database table sitting on top of my S3 files.
Configuration Summary:
- Glue Database: abrouma_scada_data
- Crawler name: block1_crawler
- Schedule: Daily at 1 AM (right after the export)
- Table name inferred: block1_temps (1 of the tables)

Step 5: Querying with Amazon Athena
With the schema cataloged by Glue, I was now able to run SQL queries directly on the CSVs stored in S3 using Amazon Athena.
Athena is serverless. I didn't have to spin up any database instances or manage infrastructure. It's fast, efficient, and perfect for reporting, dashboards, or just ad-hoc analysis.
After setting up the S3 path for query results (s3://abrouma-scada/athena-results/), I ran queries like:
select *
from block1_block1
limit 10;
Summary of AWS Services Used
Amazon S3
Amazon S3 was the core storage layer in this setup. It stores the exported SCADA data as raw CSV files, providing a scalable and durable place to archive time-series data from the plant.
AWS IAM
IAM was used to create access credentials for the Python export script. It ensured secure access to the S3 bucket and protected the data pipeline with fine-grained permissions.
AWS Glue
AWS Glue made it possible to catalog and interpret the raw files in S3. It automatically detected table structure, data types, and partitions enabling Athena to query the files as if they were in a database.
Amazon Athena
Athena provided the ability to run SQL queries directly on the S3 files using the schema defined by Glue. It required no infrastructure and gave us immediate insight into the SCADA data without duplicating it into a database.
Conclusion
Now that Approach 1 (database export method) was fully implemented and running reliably, I transitioned to Approach 2 after the Ignition license was upgraded to include the Cirrus Link MQTT modules. This second phase leverages MQTT with Sparkplug B to stream live tag data directly from Ignition to AWS IoT Core, enabling real-time data ingestion into the data lake. With this setup, we move from scheduled batch uploads to a fully event-driven architecture, opening possibilities for real-time monitoring, alerting, and dynamic dashboards.