
Introduction
After implementing Approach 1 (database export method), which ran successfully on daily schedules, the system was upgraded to a more real-time and event-driven architecture once the Ignition license was updated to include the Cirrus Link MQTT Transmission Module. This upgrade allowed for live streaming of SCADA data using MQTT with Sparkplug B, greatly improving responsiveness and data availability.
This second phase replaced batch data exports with a continuous stream of operational data into AWS, allowing near real-time analytics, alerting, and monitoring through the data lake.
Project Steps: Approach 2
Step 1: Enabling MQTT Transmission in Ignition
With the Cirrus Link MQTT Transmission module now active, I configured MQTT tags in Ignition to publish live process data to a broker. Sparkplug B (Sparkplug_B_v1_0_JSON) format was used for its efficiency in structuring industrial data and maintaining state.
- Configured MQTT Transmission settings with AWS IoT Core endpoint
- Set Sparkplug B namespace and Edge Node configuration
- Selected tag groups and published using "always" mode to reflect live values
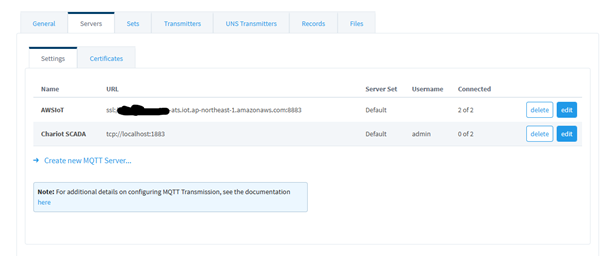
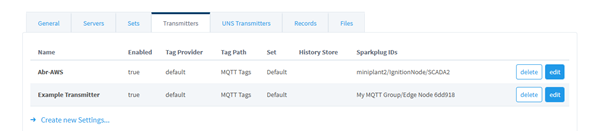

Step 2: Connecting to AWS IoT Core
To securely receive MQTT data in AWS, I registered an IoT Thing in AWS IoT Core and created a certificate/key pair for secure communication.
- Registered a thing
- Attached a policy allowing iot:Connect, iot:Publish, iot:Receive, iot:RetainPublish
- Used the endpoint from IoT Core in Ignition's broker config
Once connected, MQTT messages were successfully published to AWS.
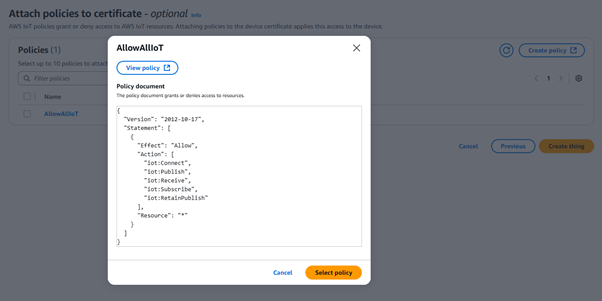
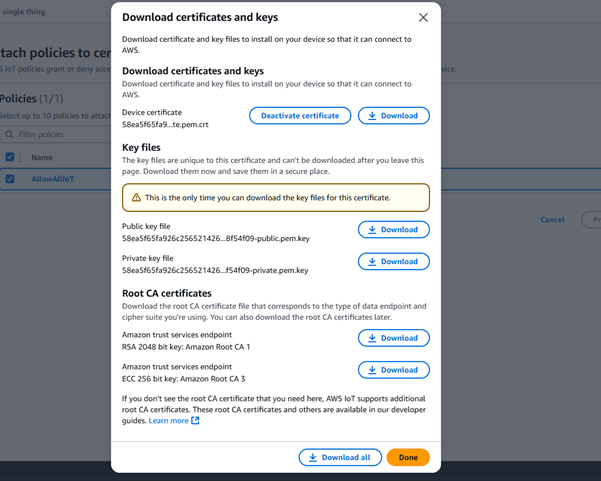

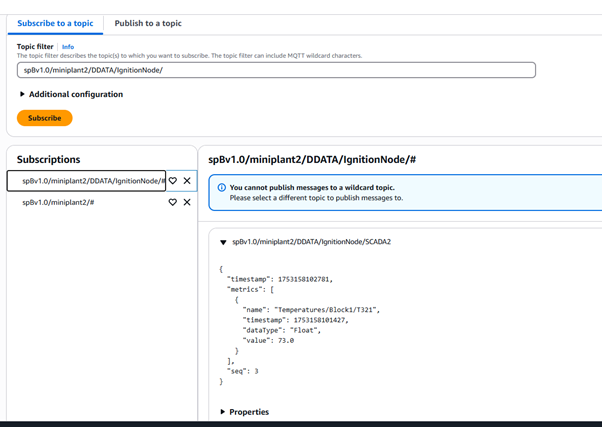
Step 3: Routing Data to S3 via Kinesis Firehose
To persist streamed MQTT data into S3, I created a Rule in AWS IoT Core that routes all incoming messages to Kinesis Data Firehose.
- SQL rule: SELECT * FROM ' spBv1.0/My MQTT Group/DDATA/Edge Node 6dd918/Temperatures'
- Action: Send matching messages to Firehose stream
- Firehose destination: S3 bucket (same as Approach 1)
I configured Firehose buffering and GZIP compression to reduce storage size and cost.

Step 4: Organizing S3 Folder Structure
Data streamed through Firehose was saved into S3 using a structured path format:
s3://abrouma-mqtt1 /year=2024/month=07/day=20/
This made partitioning easier later in Glue. File format was JSON to preserve full MQTT payload structure.
Step 5: AWS Glue Crawler for Real-Time Data
Glue was already configured from Approach 1. I added a new crawler to catalog the real-time streamed data:
- Crawler name: block1_stream
- Source: s3://abrouma-mqtt1 /
- Schedule: Every hour
- Format: JSON
- Target DB: abrouma_realtime_data
- Table: abrouma_mqtt1

Step 6: Querying and Analysis in Athena
Using the Glue Catalog, I was able to run SQL queries on the real-time data using Athena. This included queries to:
SELECT *
FROM "AwsDataCatalog"."abrouma_realtime_data"."abrouma_mqtt1"
limit 10;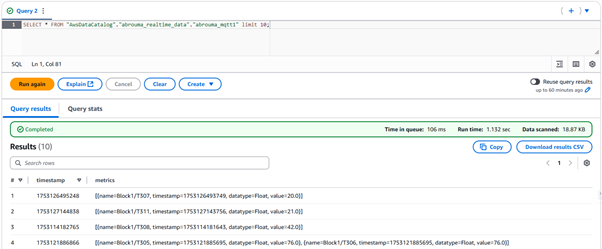
Comparison with Approach 1
| Stage | Approach 1 (DB Export) | Approach 2 (MQTT Streaming) |
|---|---|---|
| Ingestion Method | Daily Python script | Real-time MQTT over TLS |
| Source | MySQL | Ignition via MQTT Sparkplug B |
| Transport | boto3 (HTTP) | AWS IoT Core + Kinesis Firehose |
| S3 Format | CSV | JSON |
| Freshness | Daily | Seconds |
| Complexity | Simple scripting | Needs IoT config & broker setup |
Summary of AWS Services Used (Approach 2)
AWS IoT Core
AWS IoT Core acted as the secure entry point for all MQTT data published from Ignition. It managed connections, message routing, and triggered downstream delivery to other AWS services like Kinesis.
Amazon Kinesis Data Firehose
Firehose served as the pipe that streamed data from IoT Core to S3 in near real time. It supported buffering, compression, and S3 path partitioning.
Amazon S3
S3 continued to serve as the central data lake storage. In this phase, it stored real-time JSON files partitioned by date, allowing both cold and hot data to coexist.
AWS Glue
Glue crawlers cataloged the streamed JSON data into queryable tables. This enabled Athena to understand and query structureless MQTT payloads.
Amazon Athena
Athena provided the interface to analyze real-time data from the data lake using standard SQL, enabling faster insights and trend tracking.
Conclusion
Approach 2 greatly improved the responsiveness and flexibility of the SCADA data lake. Moving from batch exports to real-time MQTT streaming enabled better visibility into current plant conditions and laid the groundwork for advanced alerting and dashboards. With both approaches now in place, the system supports both historical analysis and real-time visibility, using only scalable and fully managed AWS services.
Key references:
- https://docs.chariot.io/display/CLD80/Connecting+to+AWS+IoT+Core
- https://www.cloudthat.com/resources/blog/a-guide-to-ingest-iot-data-to-kinesis-data-firehose-and-store-in-s3